
Distribution and discovery of content metadata are key to supporting audience facing products, both within and outside the �鶹Լ��. Iain Mitchell, Software Engineering Manager in Platform API, explains that due to challenges including performance and keeping up with client demands, they are moving distribution of metadata away from the traditional RESTFul API and towards a reactive approach.
The �鶹Լ�� produces a wide variety of online content for our audiences. These include programmes such as Doctor Who, news articles, educational guides and radio shows. Products both within (e.g. bbc.co.uk, iPlayer) and outside (e.g. Freeview) the �鶹Լ�� need to discover this content.
Platform API is the department responsible for distribution of the supporting metadata that enables this content to be discovered and enriched. This includes the title of the news article, playable media identifier of the Doctor Who episode, curriculum area of the educational guide and broadcast date of the radio show.
The metadata is contained within a content item specific document that is distributed to our consumers via a . Supporting our clients needs require these APIs to handle hundreds of millions of requests per day.
What we currently have
Our RESTful APIs (using illustrative urls):
- Are resource based (e.g. https://api.bbc.com/audio-visual-clips).
- Provide access via a canonical identifier (e.g. https://api.bbc.com/audio-visual-clips/ee6740b0-9fbc-9b4c-be77-4f575244fb1A)
- Have parameter based filtering for discovery (e.g. https://api.bbc.com/audio-visual-clips?about=BobDylan&createdBy=newsbeat).
- Support inclusion of extended metadata in the response via mixin parameters (e.g. https://api.bbc.com/audio-visual-clips?mixin=images).
The architecture of the APIs tends to resemble the following:
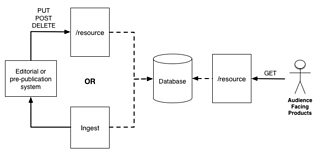
GET requests made to the API are fulfilled by retrieving the current state from an underlying database (supported by caching layers). The state of the metadata is adjusted by an editorial or pre-publication system. This is achieved by either a PUT/POST/DELETE to the RESTful API or an ingest process that moves the desired metadata into the API’s database.
Challenges
One of our biggest challenges is performance. With the high number of requests the APIs receive, we are constantly working to ensure that we can provide responses in a timely manner. Our APIs rely on in memory caches (such as and ) to ensure that duplicate requests do not cause unnecessary load on our databases.
The multitude of filters and mixins causes a wider variety of requests to hit our APIs. This results in more cache misses and a subsequent performance degradation.
A further challenge caused by the filters and mixins is that our database needs to be able to answer a wider variety of questions. This results in using a more multi-purpose database rather than one specialising in a particular function (e.g. a key-value store for retrieval by id). Often these databases are more expensive to buy and maintain, so they take investment away from developing new products for our clients.
Another challenge is the myriad of new use cases that our APIs have to fulfil. New �鶹Լ�� endeavours and a push towards more reuse of content causes our teams to be inundated with new feature requests. We have started to become the organisational bottleneck, preventing the rapid development of new audience propositions.
The final challenge we face is that our APIs are often serving a variety of different functional domains. They distribute content metadata to our audience facing products, but also answer questions from the editorial and pre-publication domains. These domains have very different profiles and expectations, take the following example:
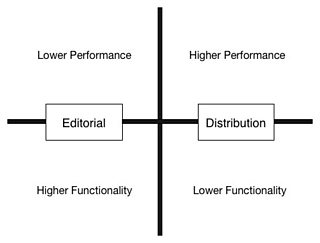
In the editorial domain we need to provide a higher degree of functionality, so that our editorial staff can author and discover content. But performance is less important; as there are significantly fewer clients and they are more willing to wait for their question to be answered. By contrast, performance is the most important factor in the distribution domain. This is due to the higher number of clients and their desire for fast responses. The amount of functionality is less important, especially if the curation and selection of content occurs in the editorial domain.
By serving multiple functional domains we are trying to optimise for performance and provide greater functionality. These are opposing goals that contribute towards some of the other challenges that I have mentioned in this section.
How could we improve?
Consider the following fictional audio-visual-clips API:
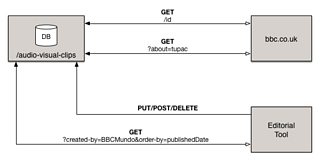
It is being used by the bbc.co.uk website to retrieve individual AV clip metadata by their canonical identifier and discover AV clips that are about certain topics (e.g. tupac). An editorial system adds, updates and deletes these AV clips and also queries the API for AV clips to embed in other types of content (e.g. Articles).
The first improvement we could make is by introducing a separate editorial API for the editorial concerns.
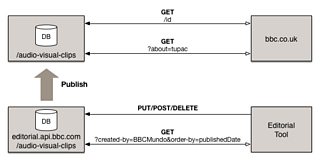
This new API would handle all interaction with the editorial system and have its own database which could be optimised to the requirements of this domain. At point of publication the AV clip metadata would also have to be added to the distribution API database.
Any editorial specific filters and mixins can now be removed from the dedicated distribution API. This would improve performance as it removes the more complex query profiles. It may also be possible to exclude editorial specific metadata from the version of the document that is promoted to the distribution API. This would reduce the size of the document and the eventual payload size to distribution clients.
Another improvement we could make is split the distribution API by separation of canonical identifier and discovery traffic.
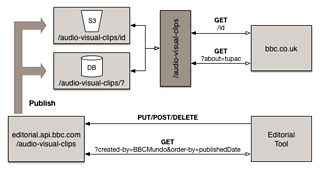
We could create two separate APIs for each of the use cases. Requesting a document by identifier could be simply served by using a file storage (such as ). Whereas document discovery may still require the power of a database. This would allow us to optimise the performance for each use case. We may also be able to introduce specific Service Level Agreements with clients for each case.
Introducing a HTTP gateway in front of the two APIs would make clients oblivious to this underlying architectural change. They would continue to interact with a RESTful resource of /audio-visual-clips.
A further improvement would be the introduction of a publication Event Store.
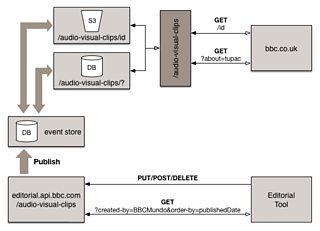
An Event Store is a database that stores a permanent transactional history of events (this is often used in an approach called . The editorial system would publish an event to this for each publication, republication and withdrawal. Adapters from each of the distribution systems would subscribe to this to receive all of the updates and update their datastores accordingly.
The advantage of this is that it would isolate the editorial system from being coupled to the distribution API(s). It also opens up an interesting possibility. What if we opened up the Event Store for clients too?
Let’s assume that bbc.co.uk is polling for AV clips about topics (e.g. tupac) to populate a cache it uses for page rendering.
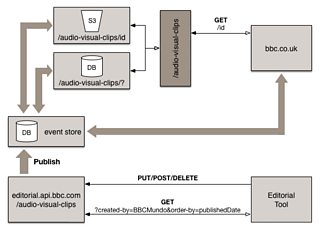
The site would no longer have to poll the API for this content and could instead subscribe to the Event Store notifications and filter these for the metadata documents it required. This is approach is referred to as being reactive.
Benefits of a reactive approach
As mentioned in the last section, using a reactive approach enables us to optimise performance for each of the distribution use cases. It also gives our systems resilience, as we have a transactional history that can be replayed if we lose one or more of our distribution datastores.
Opening up this reactive approach provides more flexibility to our clients. Rather than waiting for one of the API teams to add a new filter or mixin, they may choose to listen to the event stream and perform their own filtering. This helps prevent the API teams from becoming the organisational bottleneck for new functionality.
Switching from polling to a reactive approach will help our clients become more responsive to changes in content metadata. Rather than updating their caches on a poll to the API every minute or so, they can instantly be aware of changes and have the opportunity to reflect these to the audience.
What do our clients say?
We have had a mixed response from clients we have discussed these changes with. Many have welcomed the ability to quickly respond to metadata changes.
However, some client products do not currently store state, even in a cache. They rely upon the API to be the database of their solution. So a significant change would be required to move over to a reactive approach.
There are also some concerns that it may provide a higher barrier to entry. Particularly for new products that are trying to produce a Minimum Viable Product (MVP) to quickly test a hypothesis.
The reality is that we will provide a mixed approach to distribution in the future. Having reactive hooks that clients can subscribe to publication events, but continuing to provide a level of discovery through a traditional RESTful API.