

This is the first in a series of posts in the coming weeks about how �鶹Լ�� Online is changing, making use of the cloud and more.
Over the past few years, we in the �鶹Լ��’s Design+Engineering team have completely rebuilt the �鶹Լ�� website. We’ve replaced a site hosted on our datacentres with a new one, designed and built for the cloud. Most of the tools and systems that power the site have moved too. We’ve used modern approaches and technologies, like serverless. And we’ve refreshed the design, approach, and editorial workflow, ready for the future. Hundreds of people have been involved, over several years. And it’s just about complete.
This post is the first of several looking at the what, the why, and most importantly the how: the approach we took to creating a new site that’s ready for the future. Delivering quality technology change, quickly and effectively.
Examples of pages that have been recreated on the cloud in the past year
Context
The �鶹Լ�� website is huge. Over half the UK population use it every week. Tens of millions more use it around the world. It has content in 44 different languages. And it offers over 200 different types of page — from programmes and articles, to games and food recipes.
As is the case with tech, if you stand still, you go backwards. Until recently, much of the �鶹Լ�� website was written in PHP and hosted on two datacentres near London. That was a sensible tech choice when it was made in 2010; but not now.
The �鶹Լ��’s site is made up of several services (such as iPlayer, Sounds, News and Sport). For them all, we need to ensure they use the latest and best technology. That’s the only way to ensure they’re the best at what they do. They all need to be hugely reliable at scale, as well as fast, well-designed, and accessible to all.
And so, over the past few years, it’s been our strategy to recreate �鶹Լ�� Online. Almost every part has been rebuilt on the cloud. We’ve taken advantage of the many benefits that the cloud brings — such as the flexibility to provision new services almost instantly. And we’ve used best-practice tools and techniques — such as the React framework, and the DevOps model. We’ll look more at the approach in a moment, but first, let’s discuss the underlying principles.
Principles
Rebuilding a massive website could easily suffer from the . It’s all too easy for new projects to be over-ambitious with the requirements and the approach. A push for perfection makes it tempting to pick the most sophisticated solutions, rather than the simplest. We needed to prevent this, to ensure good value and delivery at pace. Here are some principles that helped us do this.
1) Don’t solve what’s been solved elsewhere
When building something as large as �鶹Լ�� Online, it might be tempting to consider everything from scratch. Doing so provides the most control, and leaves no stone unturned. But the cost in doing so can be huge. An off-the-shelf solution might only give you 90% of what you want, but if can be delivered in 10% of the time, it’s probably a worthy trade-off. This applies to tech, UX, business analysis, and pretty-much everything else. Most problems have already been solved somewhere else; so don’t solve them again.
A great tech example of this is the use of serverless. Around half of the �鶹Լ��’s website is rendered serverlessly with AWS Lambda. Managing virtual machines (or containers) is expensive — keeping them secure, reliable and scalable takes time. Serverless mostly solves that problem for us. And problems solved elsewhere mean we shouldn’t do them ourselves.
2) Remove duplication (but don’t over-simplify)
When there are many teams, duplication is inevitable. Two teams will each come across the same problem, and create their own solution. In some ways this is good — teams should be empowered to own and solve their challenges. But left unchecked, it can create multiple solutions that are incompatible and expensive to maintain.
As we’ve rebuilt �鶹Լ�� Online, we’ve removed a lot of duplication and difference that has built up over the years. Multiple bespoke systems have been replaced with one generic system. It’s a double win, because as well as being more efficient (cheaper), we can focus on making the new single approach better than the multiple old approaches. It’s because of this that the �鶹Լ�� website now has better performance and accessibility than ever before.
However, we must be wary of over-simplification. Replacing multiple systems with one looks great from a business point-of-view. But software complexity grows exponentially: each new feature costs more than the previous one. There reaches a point where two simple systems are better than one sophisticated system.
As an example, we chose to keep the �鶹Լ��’s World Service sites separate from the main English-language �鶹Լ�� site. The needs of the World Service (such as working well in poor network conditions) were specialist enough to warrant a separate solution. Two simpler websites, in this case, are better than one complex site.
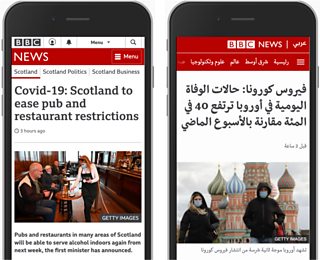
The rendering of the English-language site (left) and World Service site (right) is kept separate, to not over-complicate one solution
3) Break the tech silos through culture & communication
Creating a new �鶹Լ�� website has involved many teams. To be successful, we needed these teams to align and collaborate more than we’ve ever done before. Otherwise, we could easily create something that’s less than the sum of its parts.
It’s hard to overstate the value of communication. Without it, teams cannot understand how their work fits alongside that of other teams. And without that understanding, they cannot see the opportunities to share and align. Teams may even start to distrust each other.
Communication brings understanding, and that allows the culture to change. Instead of teams doing their own thing in isolation, they naturally share, collaborate, and flex to each other’s needs. They go beyond what is strictly their team’s remit, knowing that others will too. Which ultimately makes a better solution for everyone.
Over recent months I’ve heard teams say things like ‘that other team is busy so we’re helping them out’, or ‘we’re aligning our tech choice with the other teams’. It’s a level of collaboration I’ve not seen before. By understanding the bigger picture, and how everyone plays their part, we’ve created a level of trust and alignment that’s a joy to see.
4) Organise around the problems
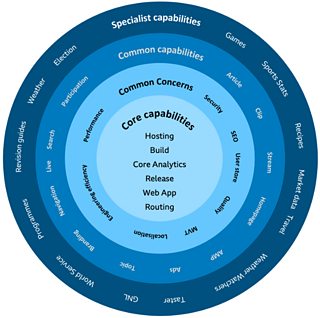
This ‘onion diagram’ helped explain how common concerns & capabilities (in the centre) should be solved once. This frees up teams to work on the more specialist capabilities in the outer rings.
Even with great culture and communication, multiple teams won’t necessarily collectively come together to build the right thing. This is, of course, the much-quoted .
“Organizations which design systems […] are constrained to produce designs which are copies of the communication structures of these organizations.”
Melvin Conway
The �鶹Լ�� has historically had separate websites — for News, for Sport, and so on. Each one had a separate team. To change that, and build one website, we needed to reorganise. But how? One gigantic team wouldn’t work, so instead we split teams into the most efficient approach. We created teams for each page ‘type’ — a home page, an article page, a video page, and so on. We also created teams to handle common concerns — such as how the site is developed and hosted. Altogether, it minimised overlap and duplication, and allowed each team to own and become expert in their area.
5) Plan for the future, but build for today
When designing large software systems, we’ve a tricky balance to find. We must plan for the future, so that we meet tomorrow’s needs as well as today’s. But we also don’t want to over-engineer. We cannot be sure what the future will bring. Requirements will change. Cloud providers will offer new technologies. The rate of change in the world — particularly the technology world — is higher than ever before.
There is no substitution for good analysis, planning, and software design. Researching the opportunities and choices available is key in ensuring a project sets off in the right direction. But we must resist the danger in over-thinking a solution, because it may be for a future that never comes.
The beauty of agile software development is that we can discover and adapt to challenges as we go along. Business plans and architectures need to evolve too, based on what we learn as the project evolves. Don’t solve problems until you’re sure they’re problems you actually have.
6) Build first, optimise later
Expanding on the above, we must be careful not to optimise too soon. Large software projects will inevitably run into performance issues at some point. It’s super-hard to predict when and how these issues will appear. So, don’t. Use the benefit of agile development to respond to performance issues only when they become real.
As mentioned above, much of the �鶹Լ�� website now renders serverlessly using AWS Lambda. At the start of the project, we were suspicious of how quickly Lambda could render web pages at scale. We had an alternative approach planned. But in the end, we didn’t need it. Performance using serverless has been excellent. By not optimising too early, we saved a huge amount of effort.
7) If the problem is complexity, start over
This principle is :
“A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.”
John Gall
Removing complexity from an existing system is hard. And in our case, we had multiple complex websites that we wanted to combine. The collective requirements of these sites would overload any one system. So, we had to start again, going back to the basics of what common abilities were needed.
8) Move fast, release early and often, stay reliable

Part of the the monthly status report we make for the WebCore project.
Finally, a very practical principle: ensure you are able to move quickly, so that you can learn and adapt. Release early, and often — even if it’s only to a small audience. As discussed earlier, predicting the future is notoriously hard. The best way to understand the future is to get there quicker.
The counterargument to this is that change brings risk. And with a popular service like �鶹Լ�� Online, reliability is critical. The �鶹Լ�� has always had a strong operational process (including 24/7 teams managing services, and a DevOps approach to ensure those who develop systems are also responsible for maintaining them). We’ve continued to invest in this area, with new teams focussing on infrastructure, and on the developer experience (DevX). We’ll go into more details in a future blog post.
Smaller releases, done more often, are also an excellent way to minimise risk.
High level technology overview
Putting the above principles into practice, here’s a super-high overview of how the �鶹Լ�� website works.
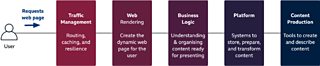
Let’s look at each layer.
Traffic management layer
First up, all traffic to www.bbc.co.uk or www.bbc.com reaches the Global Traffic Manager (GTM). This is an in-house traffic management solution based on Nginx. It handles tens of thousands of requests a second. Because of its scale, and the need to offer extremely low latency, it partly resides in our own datacentres, and partly on AWS.
For parts of our site, a second traffic management layer is sometimes used. (Internally, these are called Mozart and Belfrage). These services, hosted on AWS EC2s, handle around 10,000 requests per second. They provide caching, routing, and load balancing. They also play a key part in keeping the site resilient, by spotting errors, ‘serving stale’, and backing off to allow underlying systems to recover from failure.
Website rendering layer
The vast majority of the �鶹Լ��’s webpages are rendered on AWS, using React. React’s isomorphic nature allows us to render the pages server-side (for best performance) and then do some further updates client-side.
Increasingly, the rendering happens on AWS Lambda. About 2,000 lambdas run every second to create the �鶹Լ�� website; a number that we expect to grow. As discussed earlier, serverless removes the cost of operating and maintenance. And it’s far quicker at scaling. When there’s a breaking news event, our traffic levels can rocket in an instant; Lambda can handle this in a way that EC2 auto-scaling cannot.
A new internal project, called WebCore, has provided a new standard way for creating the �鶹Լ�� website. It’s built around common capabilities (such as an article, a home page, and a video page). It’s created as a monorepo, to maximise the opportunity for sharing, and to make upgrades (e.g. to the React version) easier. By focussing on creating one site, rather than several, we’re seeing significant improvements in performance, reliability, and SEO.
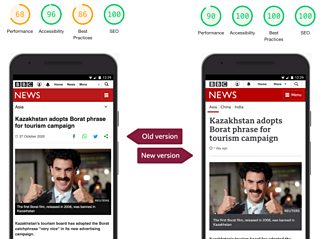
Spot the difference: comparing the older page (left) with the new cloud-based version (right). The numbers are Lighthouse performance scoring.
As discussed earlier, we’ve kept our World Service site as a separate implementation, so that it can focus on the challenges of meeting a diverse worldwide audience. (This project, called Simorgh, is open source and available on GitHub.) Our iPlayer and Sounds sites are kept separate too, though there is still a considerable amount of sharing (e.g. in areas such as networking, search, and the underlying data stores).
Business layer
The rendering layer focuses just on presentation. Logic on fetching and understanding the content is better placed in a ‘business layer’. Its job is to provide a (RESTful) API to the website rendering layer, with precisely the right content necessary to create the page. The �鶹Լ��’s apps also use this API, to get the same benefits.
The �鶹Լ�� has a wide variety of content types (such as programmes, Bitesize revision guides, weather forecasts, and dozens more). Each one has different data and requires its own business logic. Creating dozens of separate systems, for each content type, is expensive. Not only do they need the right logic, but they also need to run reliably, at scale, and securely.
And so, a key part of our strategy has been to simplify the process of creating business layers. An internal system called the Fast Agnostic Business Layer (FABL) allows different teams to create their own business logic without worrying about the challenges of operating it at scale. Issues such as access control, monitoring, scaling, and caching are handled in a single, standard way. As per our principles, we’re making sure we don’t solve the same problem twice.
Platform and workflow layers
The final two layers provide a wide range of services and tools that allow content to be created, controlled, stored and processed. It’s beyond the scope of this post to talk about this area. But the principles are the same: these services are moving from datacentres to the cloud, tackling difference and duplication as they do, and ensuring they are best-placed to evolve as �鶹Լ�� Online grows.
On to the next chapter
So, �鶹Լ�� Online is now (almost) entirely on the cloud. And it’s faster, better and more reliable as a result. We’ve discussed the key principles on how we made that change happen. And we’ve seen a summary of the technology used. More on that in later posts.
Most excitingly, this isn’t the end; just the start of something new. The tech and culture ensure we’re in a brilliant place to make �鶹Լ�� Online the best it can be. And that’s what we’ll do.
I’m massively proud of all we’ve achieved — to everyone involved, thank you.