�鶹Լ�� News Labs: linked data

Matt Shearer
Innovation Manager
Hi I’m Matt Shearer, delivery manager for Future Media News. I manage the delivery of the News Product and I also lead on �鶹Լ�� News Labs.
�鶹Լ�� News Labs is an innovation project which was started during 2012 to help us harness the �鶹Լ��'s wider expertise to explore future opportunities.
Generally speaking believes in allowing creative technologists to innovate and influence the direction of the News product.
For example the delivery of started in 2011 when we made space for a multidiscipline project to explore responsive design opportunities for �鶹Լ�� News.
With this in mind the �鶹Լ�� News team setup News Labs to explore linked data technologies.

The �鶹Լ�� has been making use of technologies in its internal content production systems since 2011.
As explained by this enabled the publishing of news aggregation pages ‘per athlete’, ‘per sport’ and ‘per event’ for the 2012 Olympics – something that would not have been possible with hand-curated content management.��
Linked data is being rolled out on �鶹Լ�� News from early 2013 to enrich the connections between �鶹Լ�� News stories, content assets, the wider �鶹Լ�� website and the World Wide Web.
�鶹Լ�� News Lab format
We framed each challenge/opportunity for the News Lab in terms of a clear ‘problem space’ (as opposed to a set of requirements that may limit options) supported by research findings, audience needs, market needs, technology opportunities and framed with the �鶹Լ�� News Strategy.
The Lab participants cover multiple disciplines including editorial staff, journalists, software engineers, developers, designers and more from across and and made sure each team had a broad discipline coverage.
A two week timeframe was chosen in order to support a good run at the ‘problem space’ and give time to incorporate the different expertises. This wasn’t just a case of hacking on top of APIs - we wanted to ensure we were incorporating the wider cross-disciplinary expertise.
In order to keep the activities rooted in reality and to minimise theoretical discussions we stipulated that the exploration should include prototyping from day two onwards.
The ‘Problem Spaces’
After producing a long list of possible ‘problem spaces’ we prioritised four areas to explore:
- Location and linked data. How might we use and linked data to increase relevance and expose the coverage of �鶹Լ�� News?
- Events and linked data.��How might we make more of �鶹Լ�� News ‘events’ using Linked Data?
- Politics and linked data.�� How might we better contextualise and promote �鶹Լ��’s Political coverage online using linked data?
- Responsive Desktop.�� How might we overcome older browser challenges to get �鶹Լ�� News’ responsive service to desktop browsers?
So the question was ‘how might we tag the �鶹Լ�� News archive with linked data and expose this data source for prototyping?’
The linked data prototyping platform – The News Juicer
In order to productively explore the linked data 'problem spaces' we quickly realised we needed a platform to give us �鶹Լ�� News in a linked data context.
Over the course of six weeks we set up a prototyping platform on the cloud codenamed The News Juicer, as it ‘juiced’ the News archive for the key linked data concepts.
As new �鶹Լ�� News articles are published to the �鶹Լ�� website they are placed in a queue on the News Juicer for .��
This job is performed as series of background processes using a combination of a natural language processing pipeline and human input for verification of results.
- Step 1 - Extract named entities
The first step in the pipeline is to extract ‘named entities’ from the raw article text. These are occurrences of proper nouns such as ‘London’ or ‘Mr Cameron’ that we can later map to concepts.
In order to extract these entities we make use of the developed by Stanford University. This suite includes a statistical model that has been trained to recognise mentions of people, locations and places within news articles based on the .������������
- Step 2 - Match to DBpedia concepts
The named entity recognition stage leaves us with a list of candidate terms that can be matched to DBpedia concepts.
In many cases there is a direct mapping between the extracted entity and the DBpedia identifier.�� For example, the extracted entity ‘London (Place)’ maps directly to .
More interesting cases arise where the entity text may not match the context it is found in. For example many football articles return results such as ‘Liverpool (Organisation)’ referring to Liverpool FC rather than the city of Liverpool.
In these cases we can use the to perform a on the entity text.
Much more difficult to resolve are truly ambiguous entities such as ‘Newport (Place)’ which could refer to any of the Newports around the UK and worldwide.
The system currently uses a very naive approach using the DBpedia concept with the closest matching identifier.��At the moment this means all Newport’s found in �鶹Լ�� News articles are mapped to the DBpedia concept which is the city of Newport in Wales.
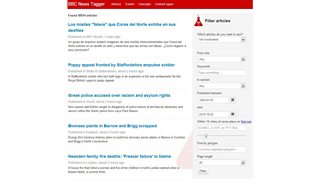
Searching for news articles using an additive filter
We are currently working to add a more advanced disambiguation stage building on �鶹Լ�� R&D’s recent work on .
In most cases the DBpedia concepts automatically matched by the preceding steps are indeed correct and the process allows us to annotate huge archives of text very quickly and cheaply.
However the process is not perfect��so the News Juicer system adds an element of human verification where editorial staff can quickly correct mistakes.
- Step 3 - Push tags into .
Finally, the concepts are pushed into the triplestore as the appropriate so that the data is available for .
- Step 4 - Allow editing of tags - The News Tagger
The user interface which allows us to subsequently add/edit/delete the tagging is a built on top of . It allows a user to search for news articles using an additive filter as shown in the screenshot above.
Selecting a news article shows the article and allows the user to moderate and edit the semantic annotations that have been applied through automation. It also allows the user to manually associate the article with one or more news events.��
��
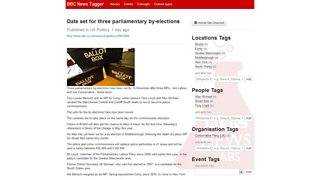
As annotations are applied in the User Interface (UI)��the triplestore is updated with the appropriate RDF including the DBpedia or event resource and the relationship between the article and the resource.
The News Juicer was deployed on the cloud in three logical tiers - a data tier, a service tier and a view tier - all hosted on a single large virtual server instance. The choice of technologies was governed by the need for low cost and rapid deployment.��
The data tier comprises:
- A PostgreSQL relational database used as the master data warehouse, persisting the basic relationship between news articles and DBpedia concepts, news events and also as scratch-pad storage for business logic data.
- An v5�� triple store used to store the RDF for news articles and the full RDF for the DBpedia concepts semantically annotated onto the content and RDF for news events and their related concepts.
The relational data service and view tier is a Ruby-on-Rails application providing:
- Background processing for the automated semantic annotation of news articles.
- A UI to allow a user to moderate and enhance the automated semantic annotations.
- A UI to allow a user to create, edit and structure news events.
- A UI to associate news articles with events.
- API to allow consumers to retrieve news articles.
The semantic service API tier is a RESTful Java web application that allows a consumer to:
- Find news articles using a flexible SPARQL where clause as .
- Find news events using a flexible SPARQL where clause as JSON.
Why we used DBpedia
DBpedia is a machine readable RDF extraction of Wikipedia primarily sourced from Wikipedia infoboxes.�� In finding a linked data set to prototype with we needed something that:
- Provided comprehensive resource coverage for the news domain.
- Has sufficiently rich inter-resource relationships to facilitate use cases that take advantage of relationships between the things that the �鶹Լ�� talks about.
- Included geographic concepts to enable prototyping of geospatial use cases.
DBpedia met these requirements and it proved to be an excellent prototyping dataset. It allowed for extensive use of automated tagging, geospatial based queries and, through its underlying ontology, the ability to create rich news aggregations by traversing the graph of people, places, organisations and their relationships.
Semantic APIs to support Rapid Prototyping
News Labs intends to exploit semantics to rapidly prototype as well as to educate �鶹Լ�� developers about semantic technologies and RDF. It was therefore important that APIs were constructed that could meet these goals.��
At the same time exposing an open SPARQL endpoint would be inherently risky.�� A consumer could potentially run a query that could use all available resources on the triple store, thus block other Labs teams.
It was also useful to let developers consume JSON representations of news articles to aid rapid web application development.
Accordingly custom web service APIs were built (in Java) that exposed the full power of SPARQL to semantically aggregate news content while ensuring that dangerous queries could not be run and returning news article JSON to the caller.
The Benefits of the News Labs approach
- Efficiency - Prototyping with all disciplines together saves time ‘in process’
Many prototypes were created and due to the preparation that went into the ‘problems spaces’ combined with the multidiscipline prototyping team these prototypes had the benefit of a real pressure cooker development environment: lots of new concepts, refinements and judgement decisions were being made very quickly and in the right direction.
This is in stark contrast to the usual cumulative lag when we need to pass ideas and specifications between disciplines, teams and organisational units.
Also the requirement to use ‘real data’ saved us time on theoretical explorations or erroneous assumptions.
- Learning about New Technologies, quickly and��safely
The developers that took part in the Labs had a hands-on and practical training opportunity with semantic data technologies.��
All disciplines involved learnt a great deal about what was practically possible with linked data and this dispelled a lot of buzz and mystery. It also provided a practical opportunity for all disciplines to try out the technologies, experiment and build prototypes without risk and many participants found this to be beneficial.
- The News Archive is tagged with semantic concepts
At the time of writing The News Juicer has extracted concepts from 62,123 �鶹Լ�� News articles, mainly from the English-speaking service but also includes 2,500 articles from , the Spanish-speaking service.
This is a tremendous legacy for future prototyping and proof of concept work and provides a safe environment to experiment with new data models and ontologies.
Outcome of the News Labs in 2012
- Prototype Screenshots
Here is some information we can share publicly - this is a summary and by no means exhaustive.
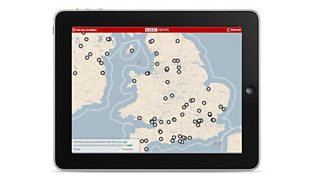
This prototype explored the relationship between the news stories and the locations they mentioned
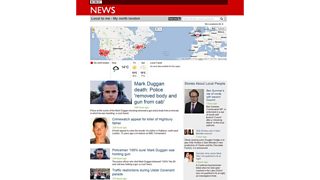
This prototype explored relevant information from �鶹Լ�� content by geolocation polygon
�鶹Լ�� News Labs - What’s next?
The platform, tools and APIs we developed for �鶹Լ�� News Labs will be in use for the foreseeable future in and also for rapid prototyping to support �鶹Լ�� News development work.
We plan to run further News Labs and will be using the News Juicer to explore News data models and product concepts as we develop them.
If you are interested in taking part in the �鶹Լ��’s innovation projects, please see the �鶹Լ�� for details of how to engage.
Thanks to:
News Labs Team in 2012: Lewis Buttress, Jonathan Austin, Russell Smith, Matt Haynes and Silver Oliver.
News Juicer by Matt Haynes, APIs & Triplestore integration by Paul Wilton, and Ruby help from Rob Nichols.
Support from �鶹Լ�� News management: Chris Russell, Steve Herrmann.
Special thanks to : Paul Wilton & Ontoba, Rob Nichols, Jody-Lan Castle, Monica Sarkar, Preethi Ramamoorthy, �鶹Լ�� R&D, �鶹Լ�� Newsgathering, �鶹Լ�� TD&A, �鶹Լ�� News & Knowledge, iPlayer, Frameworks, Louise Robey and the �鶹Լ�� Academy
Matt Shearer is delivery manager for Future Media News.
If you have a Twiter account you can follow News Lab at ��and �鶹Լ�� Connected Studio at .