

Most applications that handle video cannot avoid compression because of its high bit rate. However, compression may visibly damage the quality of pixels, limiting how much we can enjoy a video or how we can repurpose it. We’re trying to improve the appearance of compressed video by experimenting with an innovatively designed neural network. We have found promising directions for recovering compression-damaged pixels.

- Read more about this work in the preprint “” and IEEE ICASSP 2022 paper “”, both prepared by Saiping Zhang, Luis Herranz, Marta Mrak, Marc Gorriz Blanch, Shuai Wan and Fuzheng Yang.
A lot of archive video footage is not of acceptable quality to current expectations. Even a video captured only ten years ago can show compression artefacts, which are often amplified when an older video is displayed on a modern screen. While this may not look good, the video may still be valuable and could potentially be even more valuable if we could improve its visual quality.
Recent advances in machine learning have increased the potential of visual signal processing. Tools used in deep networks, such as deformable convolutions and attention-based mechanisms, can be particularly useful. They can enhance a frame’s details using other parts of the same image or from different – but similar - frames.
We have proposed an efficient version of an attention block in a deep learning framework and adapted it to be used in a hierarchical way within a convolutional neural network. We designed this scheme, called XCNET, for exemplar-based colourisation of photos before experimenting with learning-based methods to improve compressed video quality alongside our partners from the and China’s and .
Our proposed Perceptual Quality Enhancement of Compressed Video with Adaptation- and Attention-based Network (PeQuENet) consists of several modules processing compressed frames that need to be enhanced alongside their neighbouring frames.
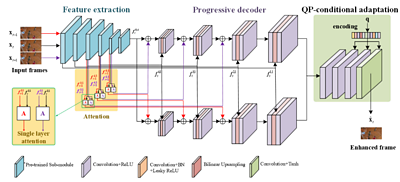
works by feeding three consecutive compressed frames separately into a pre-trained classification model (VGG-19) that analyses complex patterns and generates features that identify elements of the input content. Then six feature pairs feed into six attention blocks to exploit temporal correlations at different resolutions in the feature space, capturing global information across input frames. Besides the outputs of attention blocks, extracted features are also transmitted to the proposed progressive decoder module to prevent the loss of information caused by downsampling.
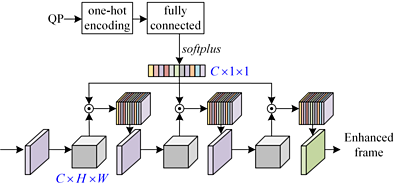
The QP-conditional adaptation module guides the frame enhancement adaptively, depending on the given QP, i.e. the impairment introduced by the compression. Our design achieves this by embedding QP information (q values) into each convolution layer of this module. This means, PeQuENet efficiently uses just one model for all QP values, making it more compact than previous networks that have attempted to enhance compressed video quality.
As we previously proposed in the approach, we use various losses, including adversarial and perceptual losses to train the network.
We have tested our research on videos compressed with H.264/AVC, H.265/HEVC and H.266/VVC. Our results show that PeQuENet can consistently provide enhanced frames in higher perceptual quality over various video resolutions and impairment levels. Our paper also shows that PeQuENet outperforms state-of-the-art compressed video quality enhancement networks quantitatively and qualitatively. This is achieved thanks to the deployed attention mechanisms that can leverage global temporal information between consecutive frames.
The detail PeQuENet adds details to textures and the way it sharpens objects affected by blur and reduces blockiness can be seen in the enhanced frame at the top of this article - the compressed frame is on the left and the enhanced frame is on the right. Additional temporal consistency tools are typically required to provide consistent results over several frames in a video.
PeQuENet is now available, open-source, in a .
The main limitation of using PeQuENet on longer and higher resolution videos is that it is time-consuming since the complexity of attention mechanisms grows rapidly with frame resolution. Consequently, we are now studying how to reduce the computational complexity of attention blocks.