

Following the success of , we’re continuing to explore object-based formats powered by our StoryKit tool. For our latest project, we commissioned to produce Instagramifaction, a documentary about the good, the bad and the ugly of the world’s fastest-growing social network.
Following research into the needs of the under-served 18 to 34-year-old audience, we wanted to know if StoryKit and the concept of object-based storytelling could help in reaching this demographic. A key insight for us was that there is not one ‘youth’ audience. This is an incredibly diverse group, not just in terms of age range, but also in terms of interests. We therefore set out to make a documentary that told a different version of the same story depending on the needs and personality traits of each viewer.
This was a significant and deliberate departure from previous interactive projects, and even previous StoryKit ones such as Click, where the focus is on the viewer choosing their own path. Although it does feature some choices during the experience, Instagramification is less focused on explicit interactivity and more on implicit perceptive storytelling. For more on this topic see my previous blog post.
- �鶹Լ�� Taster - Try Click's 1000th Interactive Episode
- �鶹Լ�� News - Click 1,000: How the pick-your-own-path episode was made
Perceptive over interactive
In the future, the �鶹Լ�� will be better at using data to learn about our audiences. The more people interact with our products through the programmes they watch on iPlayer or the podcasts and radio stations they listen to through �鶹Լ�� Sounds, the more we learn about them as individuals. Unlike some tech companies who monetize this data through targeted adverts or tailored messages influencing people how to think and even vote, the �鶹Լ�� will never pass this data on to third parties and will only use it make our content and services better. Learn more about our personal data storage project.
A person’s data could potentially allow us to curate their viewing experience, not just through the content they are recommended, but also in how that content is uniquely experienced. A 19-year-old in rural Scotland who likes pop music and reality TV might have different tastes and needs to a 33-year-old from London who likes sport and art galleries. Both, however, might still want to see a documentary about, for example, ‘the good, the bad and the ugly’ of Instagram. This pilot is an experiment to understand if and how this is possible.
How it works
Currently, the experience starts by asking each viewer a series of questions. Their responses affect how the story subsequently plays out. There are two core versions of the documentary, one geared towards entertaining and the other towards informing, each with a different presenter. Within each version, however, multiple other sections are affected by the data provided by the viewer. For example, if you’re interested in technology you get longer clips and more depth on a section about bot farms. If you live in Scotland, you are served different regional facts about Instagram than viewers from England, Wales and Northern Ireland. So although the over-arching structure stays the same, many of the elements within it are shaped according to the viewers’ unique preferences and circumstances.

We don’t, however, imagine that asking questions of each viewer upfront is the future of personalised storytelling. In the future this data could be gathered behind the scenes, building and changing over time. The actual content would be made up of lots of individual assets (or ‘objects’), which might include video, audio (broken down by dialogue, background music, etc), graphics and so on. Each of these objects will be tagged with metadata that could interact with the data of each user. Which objects are used and how they are arranged depends on what we know about the viewer.
This form of intelligent, data-driven storytelling is still some way off, but by using StoryKit to gather data upfront and build multiple routes through the story (see below), we can better understand some of the key production, editorial and user experience considerations for the future.
What we've learned so far
Throughout the development and production of the pilot, we’ve already learned so much about workflow, narrative design and the current limitations of StoryFormer (StoryKit’s authoring tool). We’ll be publishing a deep dive into the project in due course but as a taster, here are just a few of the things we’ve learned.
In terms of storytelling, we intended to create many unique versions of the documentary without creating vast amounts of costly content that often ends up hidden from most viewers – a known problem with ‘branching’ narratives. We also wanted to strike a balance between retaining a structured story with a beginning, middle and end whilst still allowing the component parts to be rearranged around the viewer. While we successfully achieved both these things, we did so through scaling down some of the initial ambitions. The solution was to create what Spirit’s Development Producer Rose McKenna termed “micro-personalisation” – lots of small moments throughout the story that combine to create subtle yet significant changes.
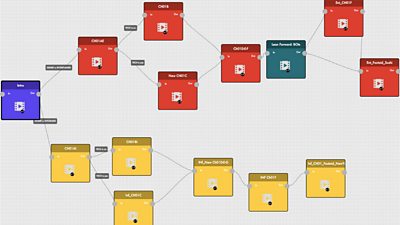
Spirit hit upon many novel ways of working such as colour-coded scripts with multiple columns for the different strands, flow charts within Google Slides and the creation of unique identifier codes for managing the media within StoryFormer. Spirit also helped the �鶹Լ��’s StoryFormer team to identify which features they need to develop further to make the tool more user-friendly for producers. These include adding overviews that preview user paths and a need for integrated design, scripting and production tools.
Perhaps the most fundamental question of all, however, is one we have yet to answer: even if we can tell cohesive, multiple versions of a story, cost-effectively and through robust user-friendly tools…do audiences actually want us to?
By this I mean, does my version of the story truly reflect what I want, or should, see? Just because I like sport, does this mean I want more of it in a documentary about social networking? Just because I like to learn new things, does this mean I don’t also at times want something light and entertaining? Are we in danger of making assumptions, dumbing down or reinforcing echo chambers? And, by putting audience needs first, are we in danger of diluting the creative authorial role of the storyteller who decides which treatment will work for which story, and delivers something the audience didn't realise they wanted? We don’t yet know the answers to all of these questions, but pilots like Instagramification will help us find them. Through �鶹Լ�� Taster we can now user-test this at scale, gathering insights to supplement qualitative user testing.
Data is only of value when you know how to apply it, and algorithms are only as good as the people who write them. Personalised, data-driven storytelling is exciting but its value will only be unlocked when it allows us to better meet the needs of our diverse audiences. We hope Instagramification is a step in this direction.
- -
- �鶹Լ�� Taster - Watch Instagramification
- �鶹Լ�� Taster - Try Click's 1000th Interactive Episode
- �鶹Լ�� News - Click 1,000: How the pick-your-own-path episode was made
- �鶹Լ�� R&D - StoryFormer: Building the Next Generation of Storytelling
- �鶹Լ�� R&D - StoryKit: An Object-Based Media Toolkit
- �鶹Լ�� R&D - Delivering Object-Based Media at Scale with Render Engine Broadcasting
- �鶹Լ�� R&D - How we Made the Make-Along
-

Future Experience Technologies section
This project is part of the Future Experience Technologies section